Apache NiFi is one of the most popular ETL platform within the open-source community. It provides a web-based user interface for creating, monitoring & controlling data flows.

Apache Nifi Terms
While working with NiFi, there are terms you need to get familiar with and these are the important aspects of NiFi. Most important building blocks are FlowFiles and Processors. Processors are responsible for creating, sending, receiving, transforming, routing, splitting, merging, and processing FlowFiles.
- FlowFile: Unit of data moving through the system. Content is the data that is represented by the FlowFile and Attributes are key/value pairs that keeps info about Flow files.
- Processor: Performs the work, FlowFiles flows between the processors.
- Connection: Links between processors.
- Controller Service: Shared services that can be used by Processors.
- Process Group: Set of processors and their connections.
Below you can find some of the key features of NiFi.
Data Provenance
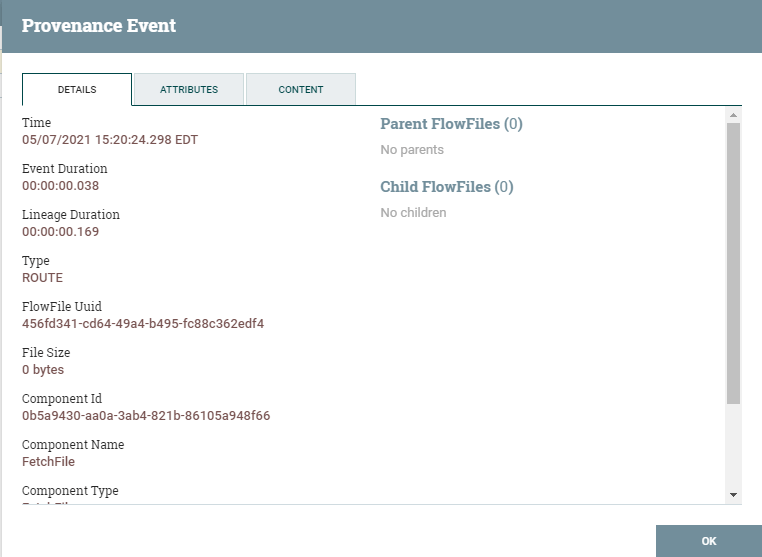
One of the features of the NiFi is the data provenance. It is used to track dataflow from beginning to end. It provides debugging capabilities of the flows and it supports retention policy.

You can click the info button for more details about each event, you can download the input and output file contents as well for debugging. It is one of the good features of NiFi as it gives visibility over each event triggered in the data flow. This feature makes troubleshooting easier for data flows.
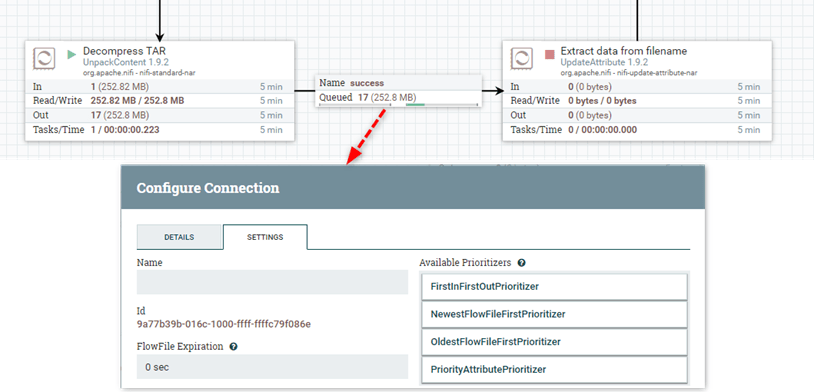
Prioritized Queueing
This feature allows you to prioritize flows per connection (remember from the terms mentioned above, connections are links between processor). You can determine what is more important for your data, you can decide based on
Time (time of arrival of flow files)
Arrival Order (The order which flow files are coming)
Attribute Based (You can even decide what to prioritize based on data itself, using attributes)
Run Duration
Higher throughput allows processors to batch many operations into fewer transactions which can increase the throughput.
This feature allows you to optimize your flow’s throughput and latency.

If we set Run Duration=2s → one scheduled run will process 10 files and then the next query will receive the FlowFiles after 2 seconds.
Expression Language
The NiFi expression Language is used to evaluate and operate against the attributes and the content of a FlowFile. Capable of ingesting, processing, transforming, and delivering data of any format. Some of the example expressions are:
Check whether the file has a specific name: ${filename:contains(‘Nifi’)}
Add a new directory to the path attribute: ${path:append(‘/new_directory’)}
Reformat a date: ${string_date:toDate(“yyyy-MM-DD”)}
Mathematical operations: ${amount_owed:minus(5)}
Component Statistics
Provides several statistics about how much data has been processed by the component. It is good way to get insights about the flows.

Back Pressure
In your data flow you might end up having too many incoming files to the flow. In this case, Apache NiFi provides back pressure feature which allows you to set thresholds. These thresholds can be set based on the number of incoming FlowFiles or based on the total size of FlowFiles.

Once this threshold is reached, source of the connection is no longer scheduled to run. When the queue is full then the connection will be marked with red.

Although there are other great features of NiFi, these are the key features worth mentioning and will help you build better pipelines and data flows.

Leave a comment